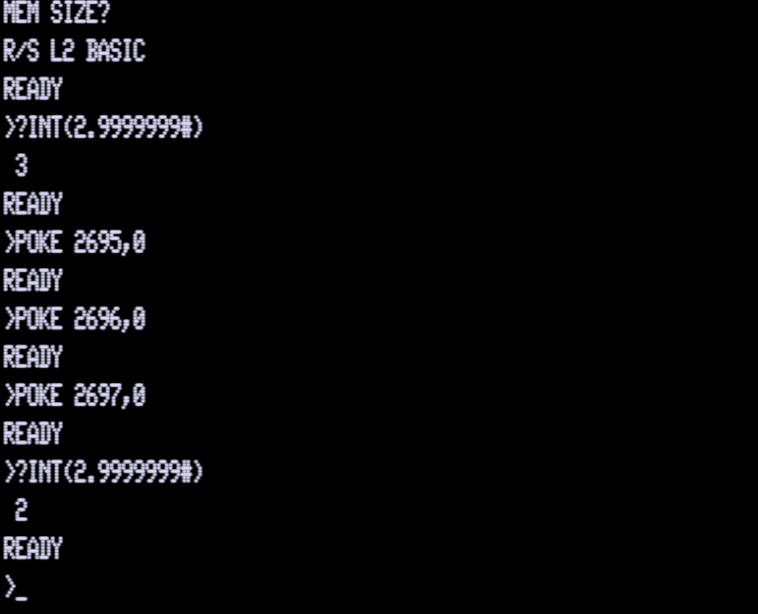
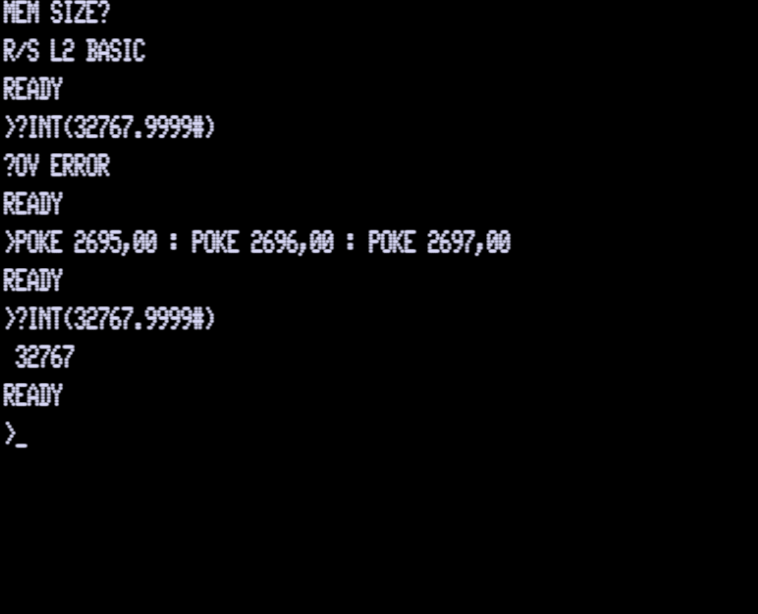
What is happening
The bug occurs in the BASIC LOG function implementation within the TRS-80 Model I ROM, starting at address 0809H. This function handles the natural logarithm calculation using a series expansion based on the atanh formula after normalizing the floating-point mantissa.
Why It's Happening
The LOG function normalizes the input argument to extract the exponent and mantissa (m), where 1 ≤ m < 2. For arguments slightly less than 1 (e.g., 0.99999994), the exponent is -1, and the mantissa is slightly less than 2. The code then checks if m > √2 (approximately 1.414) and, if so, halves m (m = m / 2) and increments the exponent by 1. This results in an adjusted mantissa slightly less than 1.
The code then computes y = (m - 1) / (m + 1), which is negative when the adjusted m < 1. The logarithm is approximated using the series expansion 2 * atanh(y) = 2 * (y + y³/3 + y⁵/5 + ...). This series works for negative y, producing a negative result. However, the ROM code computes the series assuming y is positive (or takes |y|), but fails to negate the final result when y was originally negative. As a result, the output is a positive small value instead of the correct negative value.
The specific example (LOG(0.99999994) = 8.26296E-08) is the positive approximation of the absolute value, with the slight discrepancy from the exact |ln(0.99999994)| ≈ 6E-08 due to the limited precision of the series approximation and 32-bit MBF floating-point format.
Where It's Happening
The LOG entry point is at 0809H (CALL 0955H to check for positive argument, followed by normalization).
The mantissa adjustment (halving if m > √2) happens around 081A-0828h.
The y calculation and series expansion loop (where the sign mishandling occurs) is at 0869H-0892H, with the polynomial coefficients loaded from the table at 1479h.
The final assembly of the result (where the sign should be applied but isn't) is around 0841H-0847H and 0860H-0868h (pushing loop addresses and computing terms).
How to Fix It
The fix requires patching the ROM to check if the adjusted mantissa is less than 1 (indicating y < 0) after the adjustment and before the series, setting a flag (e.g., in a temporary memory location like M40F3 or an unused register). After the series computation (around 0869h loop end at M0892), if the flag is set, negate the FP result in the accumulator (at M4121-M4125) by XORing the high mantissa byte (M4122) with 80h to flip the sign bit.
A minimal patch could be:
At an available NOP or replaceable instruction after the series (e.g., near 0890H if there's space, or redirect with a JP to a user patch area).
Add code like:
LD A,(4124H) ; Load adjusted exp
CP 81h ; Compare to 81h (for m >=1)
JR NC, no_neg ; If >=, no negate
LD HL,4122H ; High mantissa
LD A,(HL)
XOR 80h ; Flip sign bit
LD (HL),A
no_neg: ...